
MioDB论文笔记
总体介绍
原文标题为Revisiting Log-Structured Merging for KV Stores in Hybrid Memory Systems
LSM-Tree一直有周期性写停滞和写放大的问题,在传统DRAM-SSD系统架构里解决这一问题还是十分困难的。而NVM(持久化内存)有希望取代SSD,为优化基于LSM-Tree的KV存储性能提供了新的机会。
过去也有一些工作使用NVM对基于LSM-Tree的KV存储性能进行优化,但是这些工作都忽略了一个问题:传统LSM-Tree的数据序列化和压缩速度太慢,因此可能会阻塞数据从DRAM到NVM的Flush。 如果当DRAM的MemTable累积了突发性的大量写入,就需要时间来对KV项进行序列化,再将数据装入LSM-Tree的$L_0$层。因为LSM-Tree的数据序列化和压缩速度太慢,阻塞了数据从DRAM到NVM的Flush,所以存储系统就会出现写停滞。
论文的工作如下:
1、设计了多级skip list(又叫PMTable,替代LSM实现的SSTable),以充分利用NVM的字节可寻址性进行KV存储,并利用One-Piece Flushing(代替原LSM-Tree从immutable MemTable到$L_0$的Flush)来降低跨DRAM和NVM的数据序列化/反序列化成本。
2、将Zero-Copy Compaction与Lazy-Copy Compaction相结合(替代LSM-Tree中的Compaction),以减少写停滞和写放大。
3、提出了并行Compaction方案(即不同层到下一层的Compaction可以同时进行),同时还成功协调了LSM-Tree的Flush和Compaction,从而进一步减少写停滞,提高查询性能。
4、基于LevelDB实现了MioDB,并开源了代码。
设计原则
论文主张在MioDB中采用以下几项设计原则,以充分发挥NVM的优势:
1、NVM内管理KV数据的数据结构(如LSM-Tree传统的SSTable)应与DRAM Buffer的结构(如LSM-Tree的MemTable)兼容,以尽量减少数据序列化/反序列化的成本。
2、数据的Flush操作(从immutable MemTable到$L_0$层)应与$L_0$到$L_1$的Compaction协调进行,以彻底消除间隔停滞。下面给出间隔停滞的定义,如果immutable MemTable仍在Flush,而MemTable已满,则在immutable MemTable中的剩余数据完全Flush到$L_0$中的SSTable之前,不会响应新的写入请求。应用发起的写入会因此停滞一段时间,这里将观察到的这段停滞称为间隔停滞。
3、多级skip list之间的数据Compaction应足够快,且不应造成写放大问题。
4、写入性能优化不应影响KV存储的读取性能。
论文实现
MioDB Architecture
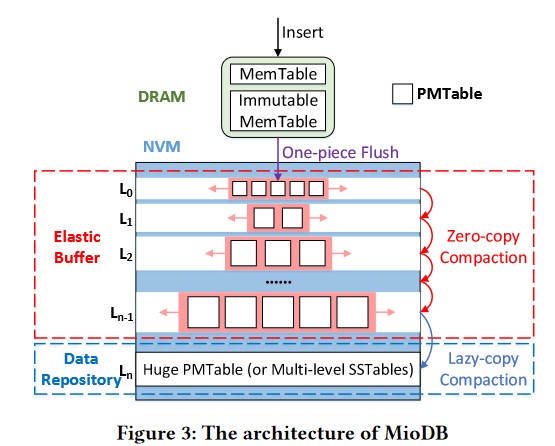
如图所示,MioDB仍然使用基于DRAM的MemTable来缓存写入请求。不过,MioDB使用skip list(PMTable)取代了传统的SSTable,以管理NVM中的持久化数据(需要注意这里没有SSD,数据最后只存放在NVM里)。在这里,论文仍然使用树状结构来表述跨多级的PMTable Compaction。然而,MioDB的逻辑结构与LSM-Tree的完全不同。在NVM中,MioDB维护着一个由$L_0$到$L_{n-1}$层的多个PMTable组成的Elastic Buffer,以及一个Data Repository。
在LSM-Tree中,每层中的SSTable数量有限,而MioDB则不同,它可以在每层中容纳无限的PMTable,而不会阻碍One-Piece Flush或跨层PMTable之间的Compaction。
论文同时提到MioDB支持将Data Repository建立在大容量SSD上,也支持在Data Repository里用多级SSTable来替代PMTable,并仍然利用LSM-Tree原有的方法进行Compaction。这是为了兼容之前已经实现并运行的应用程序。
One-Piece Flushing
当DRAM中的MemTable已满时,MioDB应该将其变为immutable MemTable,并将其Flush到NVM中。在以往的基于LSM-Tree的KV存储(包括之前几篇使用NVM进行优化的工作)中,Flush操作会对MemTable中的KV逐一序列化并复制到磁盘上的SSTable中。
论文提出了One-Piece Flushing技术,以高效地将immutable MemTable持久化到NVM中。在MioDB中,MioDB为DRAM里的MemTable和NVM里的PMTable分配了相同大小的连续内存空间。同时DRAM里的MemTable结构和NVM里的PMTable结构是兼容的。这样只需一次memcpy,就能将MemTable转换为PMTable,而无需进行数据定位和数据合并。
One-Piece Flushing可以在后台执行,不会阻塞读/写操作。当一个MemTable已满时,MioDB会将其变为immutable MemTable,并创建一个新的MemTable来进行写操作。后台线程会将immutable MemTable从DRAM Flush到NVM。在此期间,DRAM中这个原先的immutable MemTable仍可响应读取请求,直到Flush结束后这个immutable MemTable占用的内存空间才会被回收。
Zero-Copy Compaction
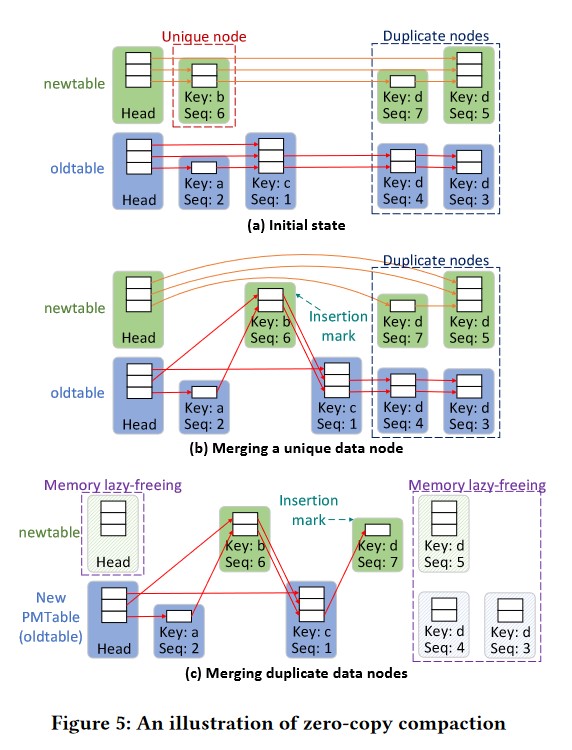
MioDB利用NVM的字节可寻址特性和skip list的数据结构,为Elastic Buffer设计了一种Zero-Copy Compaction方案。各个PMTable里的Compaction只需更新skip list中的指针,而无需移动数据节点,因此大大降低了写放大和Compaction的成本。
这里把某一级中已经存在的PMTable称为oldtable,把新插入的PMTable称为newtable。在Elastic Buffer中,每次选择每一级中最旧的两个PMTable执行Compaction操作,然后将合并后的PMTable插入下一级。图(a)展示了oldtable和newtable的初始状态。PMTable中的数据节点按Key升序排序。用Seq表示KV对的序列号。为简单起见,把具有Key x和Seq y的数据节点称为节点$N_x^y$。序列号越大,表示数据越新。具有相同Key的数据节点按Seq从大到小排序。在Zero-Copy Compaction过程中,会遍历newtable,并将节点逐个插入oldtable,最后将newtable占用的内存空间回收。
首先先看下图(a)里$N_b^6$节点,其前驱Head节点表示共有3层PMTable,$N_b^6$节点里的两个方块代表有2层PMTable里存在key为b。$N_b^6$里有一个指针指向$N_d^7$代表在一层PMTable里,同时存在key b和key d。$N_b^6$里有另一个指针指向$N_d^5$代表在另一层PMTable里,同时存在key b和key d,但是这个key d对应的$N_d^5$比$N_d^7$更旧。
再讨论下唯一数据节点和重复数据节点。看图(a),newtable一行,$N_d^7$里有一个指针指向$N_d^5$,这代表有一层PMTable里,存在2个版本的key为d的KV项,这样$N_d^7$和$N_d^5$就被认为是重复数据节点,相反的,我们也可以得出唯一数据节点的定义。
需要注意的是,Zero-Copy Compaction将每一层的newtable(实际上就是来自于上一层的oldtable)合并到该层的oldtable里,也把每一层最旧的PMTable(实际上也是oldtable)视为下一层的newtable,合并到下一层的oldtable里。
图(b)展示了如何将唯一数据节点(即key在一层的PMTable里只有一种版本)合并到oldtable中。以$N_b^6$为例。首先,使用插入标记(Insertion mark,是一个指针变量)指向$N_b^6$的地址,然后从newtable中删除$N_b^6$。插入标记使得$N_b^6$在Compaction过程中仍然可读。其次,$N_b^6$的前驱节点中的指针应指向$N_b^6$的后继节点。由于$N_b^6$的高度为2,而每一层的后继节点分别为$N_d^7$和$N_d^5$,因此前驱节点只需更改这两层的指针即可。最后,根据Key和Seq遍历oldtable,找到一个Key大于$N_b^6$的节点。这个节点是$N_c^1$。将$N_b^6$作为$N_c^1$的前驱节点,然后将$N_b^6$成功插入oldtable。
图(c)展示了重复数据节点是如何合并到oldtable中的。如果同一层里一个key在两个PMTable里有不同版本的节点(即Seq不同),称该节点为重复节点。在图(b)里上述节点$N_b^6$被执行Compaction后,继续遍历newtable并尝试处理$N_d^7$。由于$N_d^5$与$N_d^7$的Key相同,但$N_d^5$时间更早(Seq更小代表更旧),因此应直接将$N_d^5$从newtable中删除。
首先使用插入标记指向$N_d^7$的地址,然后$N_d^7$的前驱节点中的指针应指向$N_d^5$的后继节点。然而,由于$N_d^5$没有后继节点,newtable中head节点的指针被设置为空。接下来,根据Key和Seq将$N_d^7$插入oldtable。遍历oldtable,找到一个Key大于$N_d^7$的节点,或者其Key与$N_d^7$相同但Seq小于$N_d^7$的节点。在例子中,这个节点就是$N_d^4$。因此,$N_d^7$被插入到$N_d^4$的前面。然后,在oldtable中找到$N_d^7$之后的潜在冗余节点。由于$N_d^4$和$N_d^3$比$N_d^7$更早,这里只需将$N_d^7$中的指针设置为NULL,即可删除这些节点。最后,$N_d^7$被合并到(下一层PMTable里的)新的PMTable中,较早的节点$N_d^5$、$N_d^4$、$N_d^3$和newtable的head节点在逻辑上被删除(即被标记为可回收)。此时,newtable为空,并标记为可回收。被标记为可回收的PMTable占用的内存资源将在$L_{n-1}$层的Lazy-Copy Compaction后被懒释放(即Lazy-Freeing,这里的Lazy指的是不立即释放,只有在$L_{n-1}$层的Lazy-Copy Compaction后才释放)。
论文提出,利用插入标记,可以支持Compaction与Query同时进行。
Lazy-Copy Compaction
虽然Elastic Buffer能有效处理突发写入,但各级PMTable中的冗余数据(例如同一个key的更旧版本不会被查询到,是冗余的)会消耗大量NVM空间。另一方面,高度数据冗余也会降低查询性能。提出了Lazy-Copy Compaction来收集各级PMTable中的垃圾(冗余的KV项),并使用一个Huge PMTable作为Data Repository来存储剩余数据。注意到,Data Repository在MioDB架构里也是$L_n$层。
Lazy-Copy Compaction的过程如下:
1、在$L_{n-1}$里,从尾部到头部逐个遍历PMTable。对于PMTable中的每个KV对,如果$L_n$中没有这个key的旧值,就将该数据节点复制到一个新创建的节点,并将其插入到$L_n$中。需要注意的是,只有$L_{n-1}$中这个key的最新的数据节点才会被复制,其他具有相同key的更旧节点会被直接删除。
2、如果Data Repository($L_n$层)中存在这个key较旧的数据节点(即第一步的条件不成立),就地将其更新为$L_{n-1}$中最新的节点。
3、如果第一步条件成立,就会将新创建的节点插入到$L_n$中。同时,$L_n$是一个huge PMTable,而在一个PMTable里,对于同一个key,Seq更大的数据节点(即时间更新的数据节点)会放在Seq更小的数据节点左边。由于$L_{n-1}$中的数据比$L_n$中的数据新,从(第1步里的)插入位置开始遍历Data Repository,直接删除这个key的旧节点。
4、$L_{n-1}$中的所有PMTable都Compact到$L_n$中后,就可以回收$L_0$到$L_{n-1}$中为空(或标记为可回收)的PMTable的内存(Zero-Copy Compaction里提到的Lazy-Freeing)。
与Zero-Copy Compaction不同,Lazy-Copy Compaction里从$L_{n-1}$到$L_n$的Compaction需要物理复制$L_{n-1}$中最新的KV对,并将其插入到Huge PMTable中,因此Lazy-Copy Compaction的成本高于Zero-Copy Compaction。不过,由于多级Elastic Buffer可以高效处理突发写入,因此不会造成写停滞。
Parallel Compaction
由于MioDB只会对单层中最旧的PMTable进行Compaction,因此不同层中的数据Compaction是独立的。因此,论文提出采用并行的Compaction来加快所有层级的数据的Compaction的速度。
尽管RocksDB已经提供了并行Compaction的简单实现,但它对减少写停滞的作用十分有限。在MioDB中,因为Elastic Buffer每层的容量都不受限制,所以Elastic Buffer可以保证无阻塞的Compaction。同时,由于MioDB总是在单层中选择两个最旧的PMTable进行Compaction(来自上一层Compaction的PMTable至少是第三旧的),因此每层的Compaction与其他层的Compaction完全无关。由于上面两个原因,可以使用线程并行执行每层的Compaction。对于$L_0$到$L_{n-2}$之间的层,一旦单层中有两个或两个以上PMTable,就会立即进行Compaction。
Read Optimizations
在每个PMTable中,数据都是有序的。因此,PMTable内查询速度非常快。然而,即使在单层中,多个PMTable的键范围也经常重叠。在最糟糕的情况下,查询线程必须逐个检索所有PMTable。为了提高读取性能,论文提出了以下两种优化方案:
1、增加单个PMTable的容量,以利用PMTable内快速查询的优势。
2、使用Bloom过滤器缩小查询范围。
Crash Consistency
与LevelDB和NoveLSM等基于LSM-Tree的KV存储类似,MioDB利用预写日志(WAL)来保证写入DRAM Buffer里的数据的故障恢复。对一个个KV项,MioDB首先按顺序将它们添加到NVM中的持久化日志中,然后插入到DRAM里的MemTable中。
因为DRAM Buffer的日志(存储在NVM里)可用于保证崩溃后的一致性,当DRAM Buffer中的数据被Flush到NVM时,MioDB可以直接将数据复制到NVM,而不需要单独的日志。假设在Flush时崩溃了,只需要NVM里的日志就可以恢复之前写入到MemTable的数据,再次Flush到NVM里。在Zero-Copy Compaction期间,由于MioDB使用原子性写入来更新PMTable中的指针,并且不移动数据节点,因此MioDB PMTable在系统崩溃后仍能保证数据的一致性。