
MatrixKV论文笔记
引言
MatrixKV是ATC20的一篇文章,主要研究方向是使用NVM(持久化内存)优化LSM-tree数据结构。论文主要关注LSM-tree在写入时产生的Write Stalls(写停滞)和Write Amplification(写放大)并尝试解决以上两个问题。
原文题目为MatrixKV: Reducing Write Stalls and Write Amplification in LSM-tree Based KV Stores with Matrix Container in NVM。
背景
论文分析了LSM-tree具有写停顿和写放大问题。
写放大
写放大指的是写入一个 KV 对的引起的磁盘 I/O 大小和实际 KV 对的大小之比,那么在磁盘带宽有限的情况下,写放大越大,实际数据写入的吞吐量也就越小。
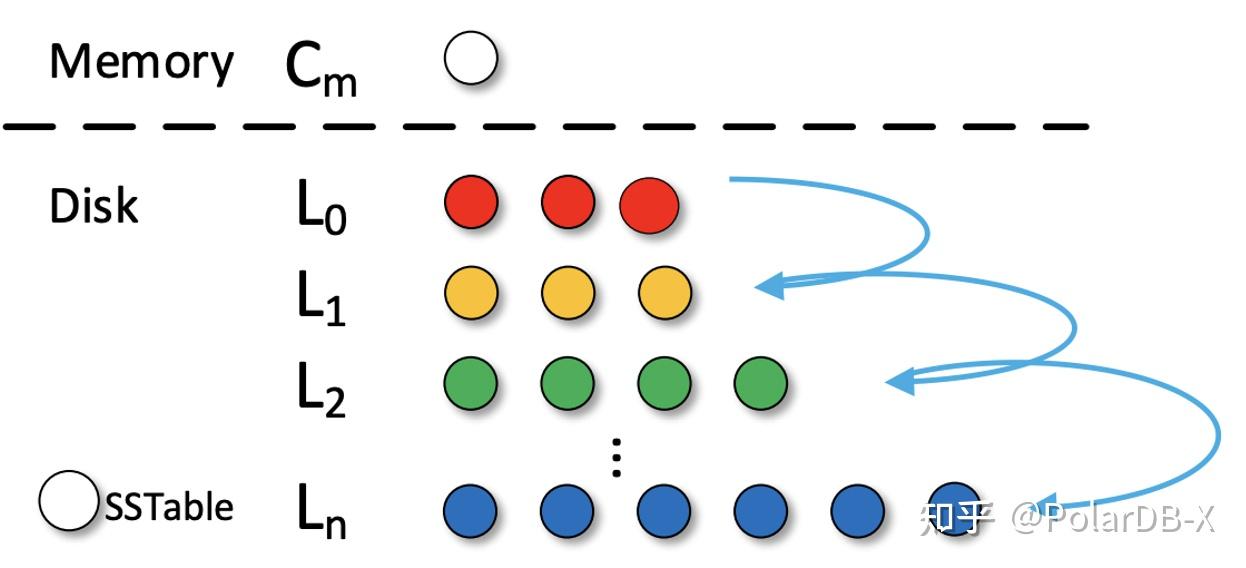
LSM-tree将数据划分成多层,为了保证每层的数据有序性,有后台Compaction线程进行多个SSTable文件合并,将上层的数据迁移到下层(如将$L_0$的数据迁移到$L_1$),观察到当$L_i$的数据与$L_{i+1}$的数据进行合并,如果$L_i$的一个key与$L_{i+1}$的key重合,LSM-tree需要将$L_{i+1}$的这个key的值进行重写,造成额外的I/O,回归到上面提到的写放大的定义,每一次对这个key的重写,都会导致写放大的发生。
可以观察到随着LSM-tree的层数增加,上述重写次数就会增多,写放大现象就更加严重。
写停滞
论文经过测试发现,在大量随机写时,吞吐量周期性的骤降到接近为0,从而会导致性能的剧烈波动和长尾延迟。
这是写停滞的典型表现。论文提出导致写停滞的主要原因是$L_0$-$L_1$之间Compaction的数据量过大。
发生$L_0$-$L_1$之间的Compaction时,就需要处理这两个Level的所有数据($L_0$的数据是无序的,SSTable之间Key Range有重叠)
论文里对写停滞的具体原因进行了分类,具体有3个:
插入停滞(Insert Stalls):如果MemTable在后台完成刷新操作之前写满了,所有的插入操作都会停滞;
刷新停滞(Flush Stalls):如果$L_0$中的SSTable数量达到上限,后台刷新操作就会被阻塞;
压缩停滞(Compaction Stalls):挂起的Compaction操作太多会阻塞前台操作;
这三种停滞都会对写性能造成影响,并导致写停滞。
设计
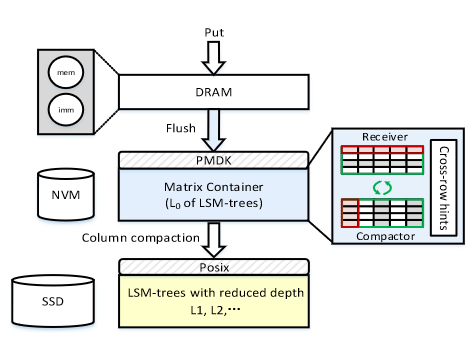
MatrixKV的整体架构如图所示,采用DRAM-NVM-SSD三层结构,使用混合存储结构的原因有三点:
未来几年NVM无法取代SSD;
相比于DRAM,NVM性能差距大;
兼顾成本和性能。
和RocksDB一样,DRAM存储原来的MemTable、ImmuTable。NVM存储$L_0$层的数据,同时设计了新的数据结构Matrix Container来管理$L_0$层,用于解决写停顿问题。SSD存储$L_1$、$L_2$等下层的数据,符合LSM-tree下层数据冷、量大的特性。 MatrixKV提出了四个设计点。
设计点1:Matrix Container
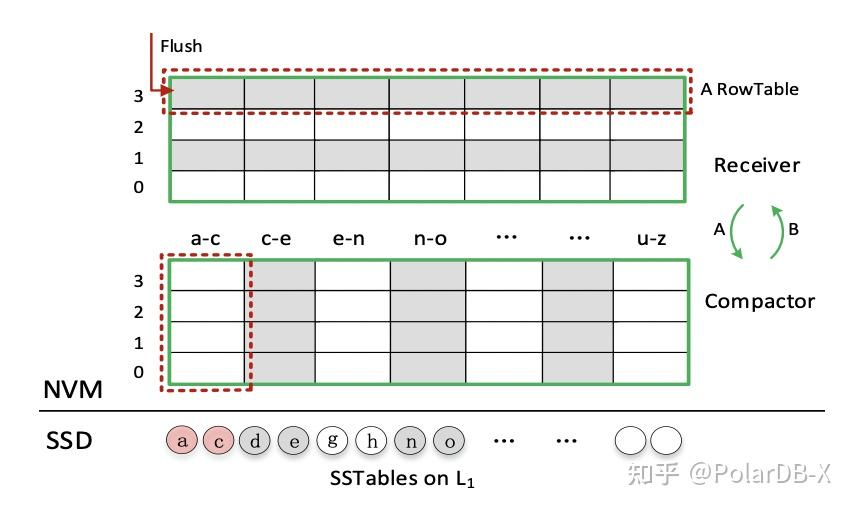
Matrix Container是LSM-tree的$L_0$层数据管理结构,其中包括一个Receiver和一个Compactor。
Receiver
在矩阵容器中,Receiver接收并保留从DRAM刷新的MemTable。每个MemTable都被序列化为Receiver的单行,并组织成一个RowTable。当Receiver的大小达到阈值(如Matrix Container容量的60%)且Matrix Container为空时,Receiver将停止接收被刷新的 MemTable,并动态地转入压缩器(Compactor)。在此期间,会创建一个新的Receiver来接收刷新的MemTable。
RowTable
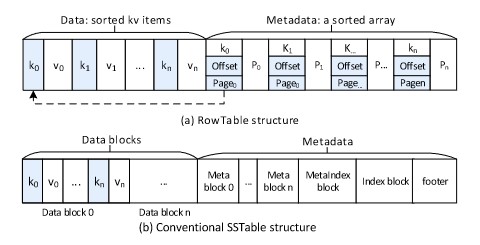
RowTable是Receiver和Compactor的一个基本存储单元,其具体实现在这里不予介绍。
SSTable是按照SSD和HDD等设备的存储单元,以块为基本单位组织的。而RowTable以NVM 页面为基本单位。除此之外,RowTable与SSTable的区别仅在于元数据的组织。因此,SSTables和RowTable的构建开销是相似的。
Compactor
Compactor用于选择和合并固态硬盘中从$L_0$到$L_1$的细粒度数据。将$L_0$的特定键范围与$L_1$的SSTable子集合并,而无需合并所有$L_0$数据和所有$L_1$数据。这种新的$L_0$-$L_1$压缩方法被称为列压缩(Column Compaction)。
设计点2:Column Compaction
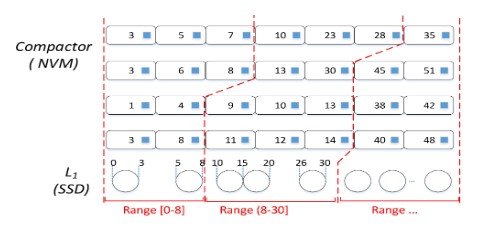
Matrix Container Compactor列压缩的过程如下:
1、MatrixKV将$L_1$的键空间分成多个连续的键范围。$L_1$中有多个连续的键范围。
2、列压缩从$L_1$中的第一个键范围开始。选择$L_1$中的一个键范围作为压缩键范围。
3、在Compactor中,在所有RowTable中同时提取这个键范围内的KV项。
4、如果该键范围内的数据量低于压缩数据量下限,则加入$L_1$中的下一个键范围。重复上述流程直至总的压缩数据量在压缩数据量下限与压缩数据量上限之间,记录这些已经选定的$L_1$键范围并合并为键范围$R$。
5、然后,所有RowTable中在这个键范围$R$内的KV项组成一个逻辑列。
6、这个逻辑列中的数据与$L_1$里键范围$R$相交的SSTable进行合并和排序。
7、最后,将生成的SSTable写回$L_1$。列压缩从$L_1$里键范围$R$后的第一个键范围开始,重复上述步骤。列压缩的键范围在整个键空间内旋转,以保持LSM-tree的平衡。
设计点3:减少LSM-tree层数
允许每一层存储更多的数据会带来两个负面影响:
首先,由于扩大后的$L_0$有更多的SSTable与键范围重叠,因此每个$L_0$-$L_1$压缩的数据量会显著增加,这不仅会增加压缩开销,还会延长写停滞的持续时间。
然后,遍历更大的未排序的$L_0$会降低搜索效率。
MatrixKV通过细粒度列压缩解决了第一个问题。由于一个逻辑列包含的数据量有限,因此列压缩所涉及的数据量在很大程度上与每一层的数据量无关。对于第二个问题,MatrixKV提出了Cross-row Hint Search来减少因$L_0$扩大而增加的搜索开销。
设计点4:Cross-row Hint Search
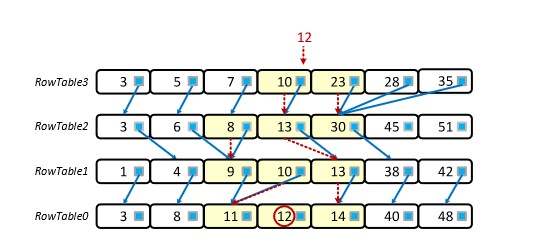
当我们为Matrix Container的Receiver建立RowTable时,我们会为元数据排序数组中的每个元素添加一个前向指针。具体来说,对于RowTable i中的键x,前向指针指向前一个RowTable i - 1中的键y,其中键y是不小于x的第一个键(即y≥x)
搜索流程如下(假设所需元素为x):
1、在最新的RowTable(即下标最大的RowTable)里二分搜索x,如果没有找到,定位小于x的最大元素和大于x的最小元素,通过这两个元素的指针,定位到下一个RowTable(即第二新的RowTable)的两个元素m和M。
2、如果m不为第一个元素,将m设置为m前一个元素。在m和M之间二分搜索x,如果找到,结束搜索,如果没找到,定位小于x的最大元素(即m)和大于x的最小元素,通过这两个元素的指针,定位到下一个RowTable(即第三新的RowTable)的两个元素m和M。
3、仿照1、2步,一直进行到最旧的RowTable,如果最旧的RowTable没有元素x,那么就去$L_1$里搜索。
测试
主要的测试结论如下(与RocksDB、NoveLSM比较):
1、Matrix可以有效缓解写停滞,性能抖动减小。
2、MatrixKV的随机写性能较好,阻塞更少,写放大更小,写性能更好。
3、MatrixKV $L_0$随机读性能比RocksDB性能更好。